Method Overview
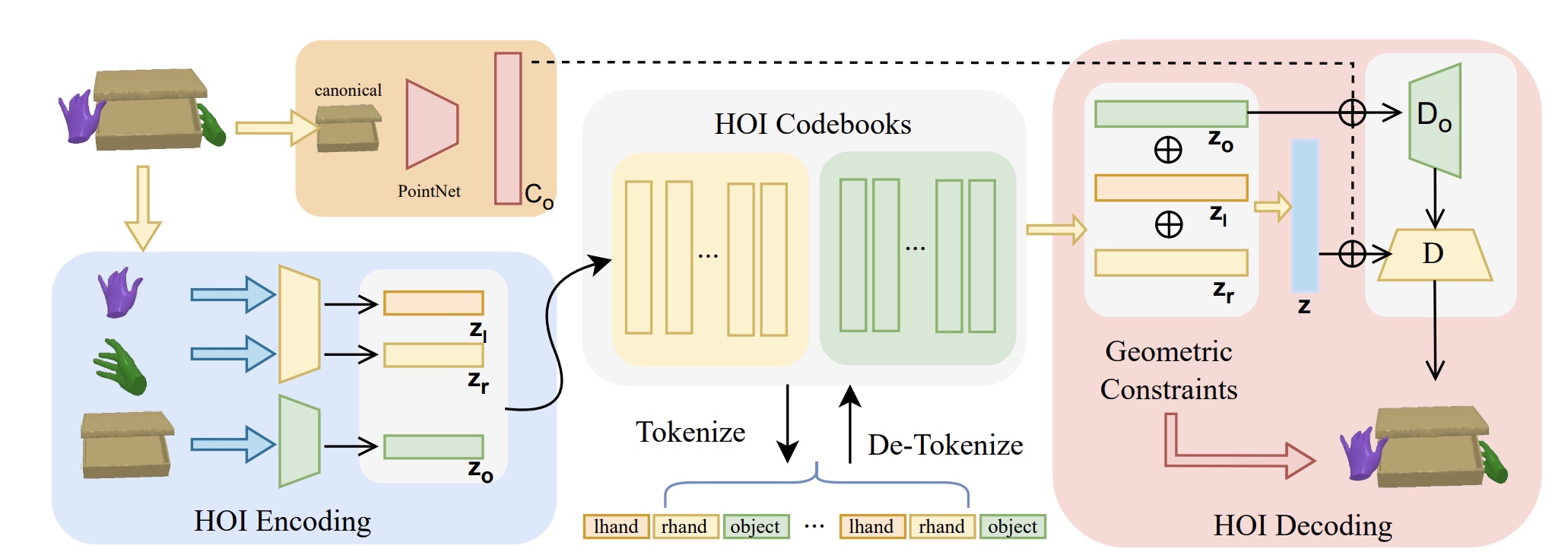
Hand-Object Decomposed VQ-VAE
Discretizes both hand and object motion sequences into tokens for compact, expressive HOI representation with improved disentanglement.
Dual Codebook Design
Uses separate codebooks for hand and object components, improving disentanglement and representation quality for better modeling.
Geometric Loss
Introduces physically grounded geometric losses to encourage realistic hand-object spatial relationships and plausible interactions.
Incremental Learning
Trains the language model in stages, starting from simpler to more complex/longer HOI sequences for robust modeling.
Motion-Aware Language Model
Employs a large language model trained to process and generate both text and HOI tokens for unified, bidirectional generation.
Flexible Conditional Generation
Given text, HOIGPT synthesizes 3D HOI sequences; given (partial) HOI sequences, it generates and completes text descriptions.